En temas de marketing online y de financiación de startups, la visión global a menudo se puede resumir en 3 variables: el CAC (Customer Aquisition Cost, o Coste de Adquisición de Cliente), el LTV (customer LifeTime Value) y la profundidad del estanque en él que estás pescando (captando clientes potenciales).
El CAC es relativamente fácil de calcular: se obtiene dividiendo el coste de marketing total del mes por el número de nuevos clientes del mes.
El LTV también es bastante fácil de calcular si tienes ya medida la recurrencia: se obtiene multiplicando el margen bruto de un pedido por la recurrencia de los clientes (el número estimado de pedidos que hará un cliente en su vida).
El margen bruto por pedido: el margen bruto medio por pedido es la diferencia entre el ingreso medio por pedido (sin IVA por supuesto) y los costes directos que incluyen cualquier coste directamente relacionado con la venta (el coste de los bienes o servicios vendidos, el transportes, la parte variable de la logística, cualquier otro coste variable que depende directamente del pedido). Aquí para estimar el LTV no se tienen en cuenta los costes fijos o los costes de marketing.
La recurrencia: por mi experiencia, lo que más complica el análisis es el cálculo de la recurrencia. Para estimarla lo correcto es hacer un estudio de cohortes. Como se trata de un análisis un pelín complejo, muchas startups no saben por dónde empezar. El objetivo de este post es de intentar explicar cómo realizar un análisis de cohortes, de ofrecer una plantilla a disposición de todos, y también de pedir vuestro feedback para mejorarlo. Por cierto, lo que sigue ya es más técnico: si quieres seguir respira hondo y ponte cómodo ;)
Modelo de estudio de cohortes:
Descargar fichero Excel
Imagen ejemplo de estudio de cohortes
Cómo actualizar el fichero con los datos de tu negocio:
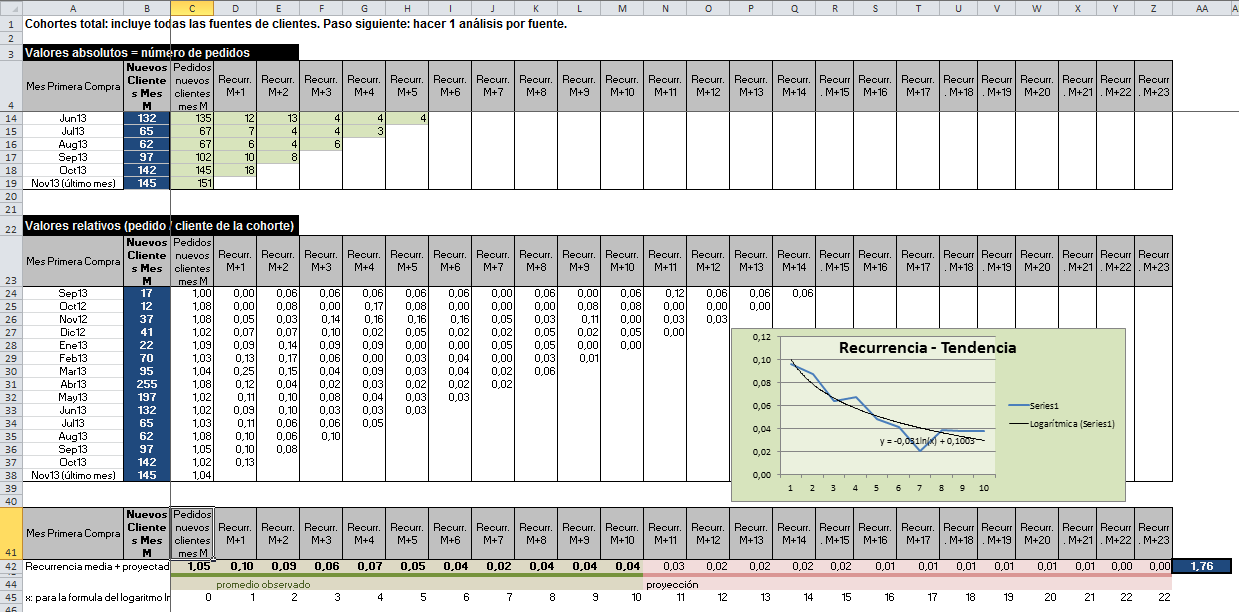
- Nuevos clientes de cada mes: completa las celdas B5 a B19 con el número de nuevos clientes del mes. Ojo: sólo nuevos clientes del mes, no clientes totales. Un cohorte son clientes que compran por primera vez en aquel mes.
- Pedidos de cada cohorte por mes: completa la primera tabla «Valores absolutos = número de pedidos«: las celdas C5 a Z19 con el número de pedidos mes a mes de los clientes nuevos del mes X.
- Pedidos / nuevo cliente: automáticamente se actualizará la segunda tabla «Valores relativos (pedido / cliente de la cohorte)«.
- Recurrencia media por mes observada: la fila 42, celdas C42 a M42, calcula la recurrencia media por mes observada para los primeros meses. En esta media puedes incluir el número de meses que te parezca relevante. Lo ideal es utilizar los 12 últimos si ya llevas más de un año, para evitar el ruido por estacionalidad. Algunos también excluyen de esta media el dato del último mes dado que éste puede variar todavía por las devoluciones por venir.
- Ajusta el área de datos de la gráfica «Recurrencia – Tendencia»: coge sólo las filas y columnas sobre las que quieres hacer el análisis: botón derecho por encima de la gráfica, «Seleccionar datos», modificar el área de datos «=’Cohortes total’!$D$42:$M$42» donde cambias «M» por la última columna con datos observados (ejemplo poner «H» si sólo tienes datos de los 5 últimos meses).
- Recurrencia media extrapolada a los meses siguientes: la gráfica «Recurrencia – Tendencia» (visible en la celda P26) muestra la evolución de la repetición media de los cohortes durante los X primeros meses (11 meses en el ejemplo adjunto). La línea azul es lo observado y la línea negra es la regresión logarítmica sobre la línea azul. Esta línea negra es la tendencia, y nos permite estimar cómo podría ser la línea azul en los siguientes meses. Si sólo tienes 2 o 3 meses de observación es probablemente mejor remplazar la función logarítmica por una regresión lineal. En otros casos es posible que una regresión polinómica o potencial se ajuste mejor a lo observado, pero por mi experiencia en general la logarítmica funciona bien.
- Gracias a la formula de la línea negra (y=-0,031ln(x)+0,1003) podemos estimar la recurrencia sobre 24 meses en lugar de estimarla sólo sobre los 11 primeros meses de nuestra observación.
- Actualiza la formula que está en Z42 (=-0,031*LN(Z45)+0,1003) con los datos que aparecen en tu gráfica (cambia «-0,031» y «0,1003» por lo que veas en tu gráfica).
- Copia la nueva formula que tienes en Z42 y pégala en las celdas anteriores Y42, X42, … hasta la primera columna donde no tienes datos observados (ej. en N42 en el ejemplo). En otras palabras en C42 hasta M42 tenemos datos observados, y en N42 hasta Z42 tenemos datos extrapolados en base a la regresión logarítmica.
- La suma de estos datos de pedidos / nuevo cliente por mes de A42 a Z42, nos da la recurrencia estimada sobre 24 meses en AA42. En nuestro ejemplo la recurrencia estimada sobre 24 meses es de 1,76, lo que significa que estimamos que cada nuevo cliente captado hará de media 1,76 pedidos. Si quieres estimarla sobre menos de 24 meses basta con incluir menos columnas en la suma.
- Luego calculas el LTV multiplicando tu margen bruto por pedido por la recurrencia. Por ejemplo si el margen bruto fuera de 20€ por pedido, el Lifetime Value de un cliente sería de 35,2€.
- Con esta estimación de LTV ya sabes hasta cuánto estás dispuesto a gastarte de media por un cliente. Con un LTV de 35,2, lo razonable sería no pasarse de 35,2€ de CAC medio (por encima de 35,2 los clientes nos cuestan de media más de lo que valen).
Agradecimiento: gracias a Clever PPC por el modelo original de esta hoja de cálculo, a Marta y a Fernando Constantino por revisar este post y a José Cabiedes por haberme enseñado sobre cohortes.
Actualización 22/11/2013: Nacho Hernández de Yaysi lo explica muy bien en lenguaje más natural en su comentario:
Para asegurarme de que lo entiendo bien y por si a alguien le puede ayudar a comprenderlo también, lo que entiendo que estamos haciendo aquí es algo así como calcular la probabilidad de que un usuario que ha comprado en un mes determinado por primera vez realice otra compra en cada uno de los meses posteriores. Para calcular esta probabilidad usamos datos históricos, por ejemplo, cuantas personas que compraron por primera vez en mayo de 2013 compraron también en junio, julio, etc… Así, si tuvimos 100 ventas a clientes nuevos en mayo y de esos 100, 10 nos vuelven a comprar en junio la probabilidad de que un comprador de mayo compre en junio es de un 10%.
Al agregar todos los datos lo que obtenemos es la probabilidad de que alguien que compra en el mes N por primera vez realice otra compra en el mes N+1, N+2… Así si utilizamos años completos en los datos históricos se elimina la estacionalidad.
Cuando se suman todos los datos históricos más los extrapolados lo que obtenemos es una estadística sobre cuantos pedidos nos va a hacer un usuario (de media) en un período determinado.
También te podría interesar:
¡comentarios bienvenidos! así podremos ir mejorando la plantilla y este post.